【OpenAI o1背后技术】Sef-play RL:LLM通过博弈实现进化
OpenAI o1是经过强化学习训练来执行复杂推理任务的新型语言模型。特点就是,o1在回答之前会思考——它可以在响应用户之前产生一个很长的内部思维链。也就是该模型在作出反应之前,需要像人类一样,花更多时间思考问题。通过训练,它们学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。重点在于,OpenAI 的大规模强化学习算法,教会模型如何在数据高度有效的训练过程中利用其思想链进行高效思考。换言之,类似于强化学习的 Scaling Law。
现如今LLM进化的途径有三种:

- 行为克隆:通过让LLM学习Positive,从而教会模型进行指令遵循;
- RLHF/DPO:通过引入Positive和Negative,让LLM知道偏好信息,从而实现对齐;
- Slef-play:引入一种博弈的过程,让LLM实现Weak-to-Strong
Self-play基本形式
经过SFT和RLHF的模型,通过自我进化增强的形式实现Weak-to-Strong过程。LLM中的Self-play有两个先决条件:Generator 和 Verifier。
Self-play相当于Generator与Verifier之间的对抗博弈,Verifier十分关键,构造高质量数据用于RL/Reward训练。常见的判别式RM,大模型作为裁判(LLM as a judge)等模式的判定准确率仍显不足,我们急需一种能够scaling起来的方式。
Google DeepMind提出一种经典的方法(Generative Verifiers: Reward Modeling as Next-Token Prediction)如下所示:

对于一个问题和答案,首先按照生成式模型的方法给出自然语言的判断,然后再给出RL所需要的标量数值。通过CoT的形式让LLM充当Verifier并给出判断正确与否的思考过程。Verifer和generator之间也可以通过信息密度更高的自然语言的方式进行互动。相当于RM监督policy的时候,不仅告诉了每条答案的评分还详细给出了错误的原因。
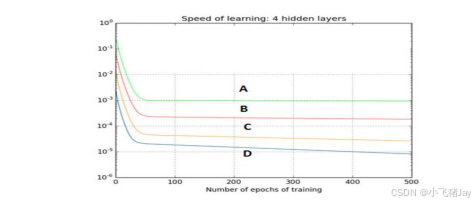
Verifier判别出来的正例和负例可以同时利用起来!在强化学习中,引入负例可以更有效地提升大语言模型的推理强度。在论文《RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold》中表明,数据利用效率更是达到了仅使用正例的八倍,即对于推理来说一个巨大的采用空间内,做错的可能性在起初要大大高于能够做对的概率。如果无法充分利用负例的数据价值,学习效率就会大打折扣。

如上图所示,如果只在Positive上进行SFT训练,那么就需要接近8倍的训练数据/时间/资源来达到相同较低的Test Error时对应充分利用Negative数据的RL方法。
Self-play中的Inference-time Scaling Law
Google DeepMind提出的一种Inference Time Scaling Law(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)揭露出在推理阶段进行Scaling相比于训练更加有效。文中探索了两种有效的test-time scaling策略:
- 通过搜索的方式结合过程奖励模型进行判断,例如PRM(过程监督奖励模型) + MCTS(蒙特卡洛树搜索)
- 在推理时不断按照上下文进行模型分布调整。
那么推理阶段的Scaling有如下几种形态:
- 宽度Scaling Law——Best-of-N:给定一个prompt(状态),并行地让LLM Generator生成若干推理结果,然后让Verifier对所有结果进行评判,并将得分最高(或者类似Self-Consistency投票法)选出最合适的答案。此时Scaling Law属于宽度(并行)方向
- 深度Scaling Law——CoT:另外一种就是增加模型预测的“步数”,相当于让模型在给出答案之前生成较长的思考过程,从而约束LLM进行“深度思考”,从而得到靠谱的答案。这也是CoT的方式,即在推理阶段集中靠生成一定数量的token来实现Scaling。此时的Scaling Law属于深度串形方向。
- 广深结合:OpenAI o1则是在Inference阶段结合了两者Scaling Law方向。在某一个状态进行Self-play过程中,通过蒙特卡洛树搜索(MCTS)展开若干可能的推理路径,并基于Verifier给出每一步和最终结果的判定和奖励。Self-play RL的推理态即是在这种guided search的模式下不断地获取到Positive和Negative推理数据,并通过RL进行自我进化。这一过程中考虑到的Scaling Law集中在(1)扩大搜索宽度有多少(探索与利用的trade-off)?以及(2)选择哪个方向可以在有限的深度范围内进行多步推理并得到预期答案?
Self-Play RL = Search + Memory
什么是Self-play RL呢?RL本质上就是探索与利用的Trade-off:
- Search——探索过程,Trial-and-Error不断地进行试错和尝试,根据推理结果的反馈进行反复思考、回溯;
- Memory——利用过程,记住之前探索过程中积累的经验,并在下一次遇到类似状态时选择最好的路径;
Self-play RL可能的实现技术框架
一种可能的Self-play RL技术框架就是Generator + Verifier + RM的组合,如下图所示:

上图所示,其中实线代表LLM Generator生成结果,虚线代表Verifier对推理过程和结果进行判定
Generator和Verifier组合为一个Self-play System,通过Actor-Critic形式进行RL,通过引入TD-error实现参数更新。
Self-play过程中考虑到宽度和深度Scaling Law的结合,所需要的计算规模甚至会达到训练阶段的100~1000倍。正是这种Scaling Law使得LLM能够探索到足够多的推理路径,并利用这些Positive和Negative作为经验通过RL训练成为LLM的记忆。
Reward Model则可以是通过Bradley-Terry Model训练的标量奖励函数,在整个Self-play过程中充当一个Discriminator从而增强Verifier的能力,而Reward Model则可以充分利用Self-play过程中产生的反馈结果(Positive和Negative)进行训练。
参考资料:
- https://zhuanlan.zhihu.com/p/720106482
- OpenAI o1 Survery:https://github.com/wjn1996/Awesome-LLM-Reasoning-Openai-o1-Survey/tree/main
【大模型&NLP&算法】专栏
近200篇论文,300份博主亲自撰写的markdown笔记。订阅本专栏【大模型&NLP&算法】专栏,或前往https://github.com/wjn1996/LLMs-NLP-Algo即可获得全部如下资料:
- 机器学习&深度学习基础与进阶干货(笔记、PPT、代码)
- NLP基础与进阶干货(笔记、PPT、代码)
- 大模型全套体系——预训练语言模型基础、知识预训练、大模型一览、大模型训练与优化、大模型调优、类ChatGPT的复现与应用等;
- 大厂算法刷题;